
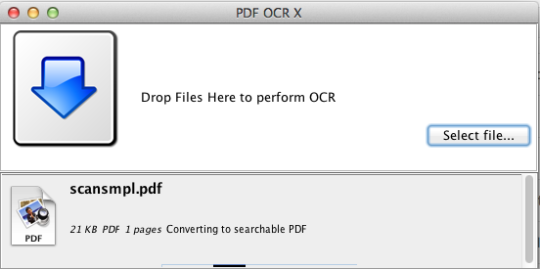
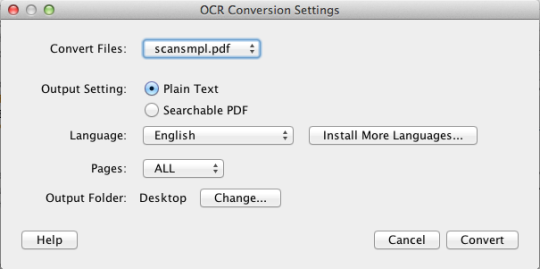
PDF OCR X е проста програма за изтегляне и пускане за Mac OS X, която преобразува PDF файловете и изображенията в текстови или PDF документи с възможност за търсене. Той използва усъвършенствана технология за разпознаване на символи (OCR), за да извлече текста на PDF файла (или изображението), дори ако този текст се съдържа в изображение. Това е особено полезно за работа с PDF файлове и изображения, създадени чрез функцията Сканиране към PDF в скенер или фото копирна машина. Поддържа над 60 езика за OCR. Оптичният двигател е базиран на Tesseract. Изданието на Общността поддържа един PDF страници (или първата страница на многостранични PDF файлове). За многостранна PDF поддръжка трябва да преминете към Enterprise Edition.
Какво ново в това издание:
Версия 2.1.1 добавя поддръжка за Mojave , и подобрява потребителския интерфейс на дисплеите на ретината.
Какво е новото във версия 2.0.8:
Фиксиран проблем при работа с някои PDF файлове с ротация. >
Ограничения :
Изданието на общността е ограничено до PDF страници и изображения на една страница.


Коментари не е намерена