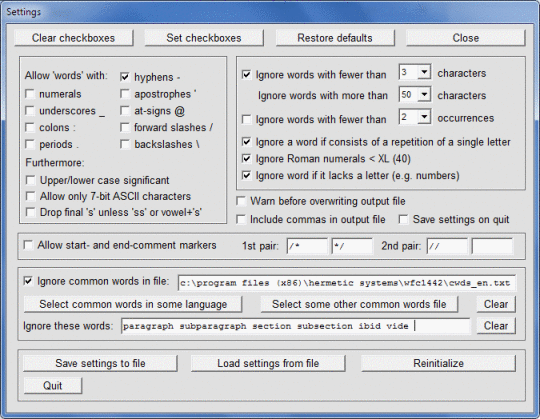
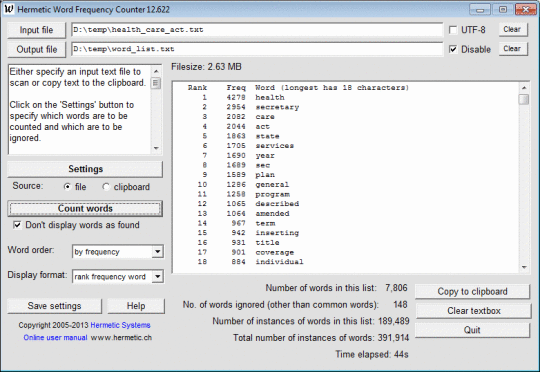
Този софтуер сканира MS Word docx файл или текстов файл (включително HTML и XML файлове) с текст кодиран чрез ANSI или UTF-8 и преброява честотите на различни думи. Думите, които се намират и показват, могат да бъдат подредени по азбучен ред или по честота. Могат да се посочат символи, които могат да се появяват с думи, за да може програмата да разреши или да забрани думи с цифри, тирета, апострофи, долни черти или двоеточие, да пренебрегват кратки думи или да се появят рядко. значителни или не, и да игнорират думи (напр. общи думи като "това"), съдържащи се в определен файл. Този софтуер може да се използва с текст на езици, различни от английски, по-специално с френски, немски, италиански и испански текст. Езикът на текста се открива автоматично и евентуално се зарежда съответният файл "обикновени думи" (с думи, които трябва да бъдат игнорирани). Резултатите могат да бъдат записани в изходен файл и след това могат да бъдат прочетени в Excel за по-нататъшна обработка.
Какво е новото в тази версия:
Версия 19.36:
Новите във версия 19.26:Подобрена инсталация.
във версия 18.22:
Подобрена обработка на XML файлове
Какво е новото във версия 16.52:
Версия 16.52 може да включва неопределени актуализации, корекции на програмните грешки.
Какво е новото във версия 16.42:
Версия 16.42 може да включва неопределени актуализации, подобрения или корекции на програмни грешки. > Какво е новото във версия 16.22:
Версия 16.22 може да включва неопределени актуализации, подобрения или корекции на програмни грешки.
Какво е новото във версия 15.52:
Версия 15.52 фиксирана грешка в разпознаване на текстови файлове, кодирани с UTF-8.
Какво е новото във версия 14.42:
Добавена е поддръжка за файлове със смесен английски / китайски текст.
<> силни ограничения :
Проучване за 30 дни, ограничена функционалност
Коментари не е намерена