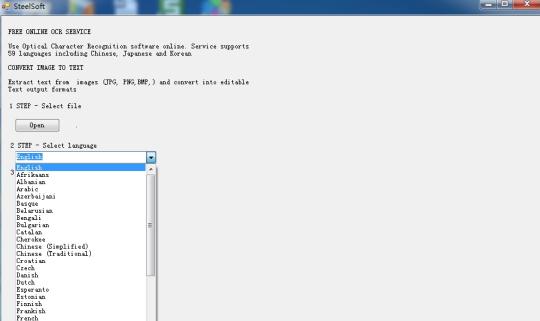
Разпознаване на текст от изображения с помощта на тесеракт OCR Engine базирани на технологията на облак.
Използвайте Optical Character Recognition софтуер онлайн. Service поддържа 59 езика, включително китайски, японски и корейски. Извличане на текст от изображения (JPG, PNG, BMP, TIF) и конвертирате в редактируеми Текст изходни формати.
Тя се основава на облак технология, както и много известен двигателя OCR (тесеракт OCR Engine), така че има само стотици KB в размер, но тя може да извлечете текст на 59 езика, от изображенията.
Той поддържа повече езици: български, каталонски, чешки, датски, холандски, английски, фински, френски, немски, гръцки, унгарски, индонезийски, италиански, латвийски, литовски, норвежки, полски, португалски, румънски, руски, сръбски, словашки, словенски , испански, шведски, тагалог, турски, украински, виетнамски и т.н.
<силни> Какво ново в тази версия:..
Версия 5.0 включва подобрения UE


Коментари не е намерена