Софтуер снимки:
Софтуер детайли:
Версия: 3.4
Дата на качване: 10 Dec 15
Розробник: Martin Jericho
Разрешително: Безплатно
Популярност: 12
Тя може да редактирате от страна на сървъра и от страна на клиента тагове, докато възпроизвежда дословно всяка непризната или невалиден HTML.
Той също така осигурява високо равнище функции за манипулиране на HTML форма
<силни> Характеристики :.
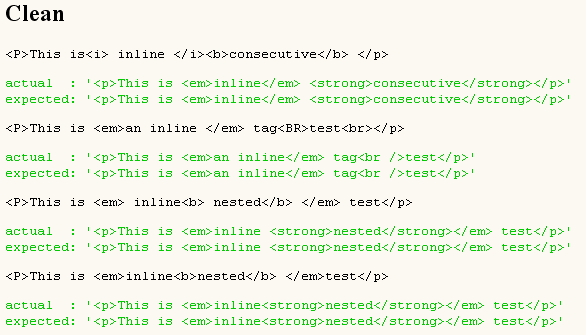
- Наличието на неправилно форматиран HTML не пречи разбор на останалата част от документа, което го прави идеален за използване с библиотека & quot; реалния свят & quot; HTML че дросели други парсери.
- ASP, JSP, PSP, PHP и Мейсън сървърни тагове, които са изрично признати от парсера. Това означава, че нормалната HTML все още се прави разбор и правилно, дори ако има сървърни тагове вътре в тях, която е обща за пример, когато динамично създаване елемент атрибути.
- Нов поток базирани разбор опция с помощта на класа StreamedSource, която позволява паметта ефективна обработка на големи файлове с помощта на итератор събитие. Това е по същество Stax алтернатива със способността да обработва HTML и не-валидиране на XML, както и няколко други функции не са налични в други стрийминг парсери.
- В стандартния си вид тя не е нито едно събитие, нито дърво базирани анализатор, а по-скоро използва комбинация от просто търсене на текст, ефективно признаване маркер и позиция таг кеш. Текстът на целия документ източник първото зареждане в паметта, а след това само съответните сегменти избраните за съответните герои на всяка операция за търсене.
- В сравнение с дърво базирани анализатор като DOM, изискванията за памет и ресурси могат да бъдат далеч по-добре, ако само малки части от документа, трябва да се прави разбор или модифицирани. Неправилно или неправилно форматиран HTML могат лесно да бъдат пренебрегнати, за разлика от дърво, базирани парсери, които трябва да идентифицират всеки възел в документа от горе до долу.
- Спрямо събитие базирани анализатор като SAX, интерфейсът е на много по-високо ниво и по-интуитивен и представяне дърво на йерархията на документ елемент е лесно да създава, ако е необходимо.
- The започват и завършват позиции в документа източник на всички анализирани сегменти са достъпни, което позволява промяна на само избрани части от документа, без да се налага да се реконструира целия документ от дърво.
- Номерът на ред и колона на всяка позиция в изходния документ са лесно достъпни.
- Осигурява един прост, но цялостен интерфейс за анализ и манипулация на HTML елементи за управление, включително извличането и населението на начални стойности, и конверсия само за четене или за показване на данни режими. Анализ на управление на формуляра също позволява на данни, получени от формата, която се съхранява и представя по подходящ начин.
- Вградена функционалност за извличане на целия текст от HTML маркиране, подходяща за хранене в текстово търсачки като Apache Lucene.
- Вградена функционалност да оказват HTML маркиране с проста форматиране на текст.
- Вградена функционалност за форматиране на HTML сорс код, който прави отстъп елементи според дълбочината им в йерархията на документ елемент. (Кликнете тук за онлайн демонстрация)
- Вградена функционалност за компактен HTML сорс код, като премахва всички ненужни бяло пространство.
- Персонализирани видове етикет може лесно да бъде определено и регистрирано за признаване от парсера.
Какво ново в тази версия:.
- Добавено Source (File) конструктор
- Добавено OutputDocument.getSegment () метод.
- Добавено OutputDocument.remove (инт започне, край инт) метод.
- Добавено Renderer.setHRLineLength () метод.
- Добавено RenderToText.jsp уеб приложение проба.
- Добавено Segment.getRowColumnVector () метод.
- откриване Encoding предприятието игнорира общи кодировки, посочени в мета тагове, които имат размер на код единица несъвместима с предварителния кодиране.
Какво ново версия 3.1:
- Корекции на грешки:
- безкраен цикъл на Segment.getAllStartTags ()
- безкраен цикъл на Segment.getAllElements ()
- Segment.getFirst * методи върнати сегменти извън сегмента на очертаващ.
- Фиксирани грешки документиране Segment.getAllElements методи.
- Добавено StreamedSource клас.
- Промени, които биха могли да повлияят на поведението на съществуващите програми:
- Променен ParseText от клас да се намесвам.
- Segment.getNodeIterator () вече връща символни препратки като отделни възли.
- Добавена статично Source.LegacyNodeIteratorCompatabilityMode имот временно да възстанови Segment.getNodeIterator () функционалност на този от предишните версии.
- Премахнато Чар [] методи, основани от търсенето в ParseText.
- Добавено CharacterReference.appendCharTo (Appendable) метод.
- Добавено OutputDocument (Segment) конструктор.
- програма Добавено StreamedSourceCopy проба.
<> Li Segment.getAllElements методи не се върнат всички затворени елементи при някои обстоятелства.
<> Ли Добавен етикет търсене методи, основани на атрибут стойност регулярни изрази.
<> Ли Добавен етикет методи за търсене базирани на HTML клас атрибут.
Коментари не е намерена